이번엔 드디어 저도 답을 모르고 시작하는 실전 데이터 분석에 대해서 다뤄보겠습니다. 주제는 이미 Kaggle에서 마감된 과제이지만, 그래도 해보고 싶었던 Sentimental Analysis에 대해서 해보려고 합니다. (자료출처 : Kaggle) Kaggle은 open competition으로 굉장히 유명하고 잘 정립된 사이트이니 data mining에 관심있으신 분들은 꾸준히 도전해보고 연습하시면 굉장히 많은 도움이 될 것입니다.
Continue reading
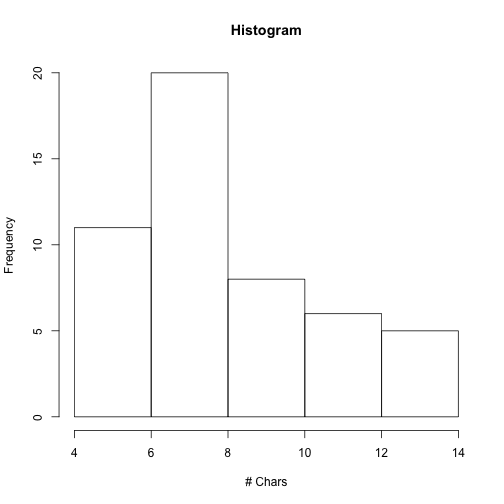
저번 포스팅에 이어서 계속해서 R로 하는 text processing을 알아보겠습니다. 일단은 hist함수를 통해서 주 이름의 글자수를 histogram으로 나타내 보겠습니다.
states=rownames(USArrests)
hist(nchar(states), main = "Histogram", xlab = "# Chars")
 그럼 이번엔 주 이름에서 모음의 분포는 어떻게 될까요?
그럼 이번엔 주 이름에서 모음의 분포는 어떻게 될까요? gregexpr을 이용해서 해당 패턴이 언제 등장하는지 알 수 있게 됩니다.
Continue reading
이번에 우리가 예제로 사용할 dataset은 USArrests라는 미국 각 주의 범죄율에 관련한 데이터입니다. 물론 우리는 text processing에 관심이 있기 때문에 주의 이름만을 참조할 예정입니다 :) 간단하게 dataset이 어떻게 생겼는지 확인해 봅시다.
## Murder Assault UrbanPop Rape
## Alabama 13.2 236 58 21.2
## Alaska 10.0 263 48 44.5
## Arizona 8.1 294 80 31.0
## Arkansas 8.8 190 50 19.5
## California 9.0 276 91 40.6
## Colorado 7.9 204 78 38.7
각 행이 하나의 주라는 것을 알 수 있죠? 각 행의 이름이 주의 이름이기 때문에 rownames함수를 사용해 이들을 vector형태로 가지고 오겠습니다.
Continue reading