저번 포스팅에 이어서 계속해서 R로 하는 text processing을 알아보겠습니다. 일단은 hist함수를 통해서 주 이름의 글자수를 histogram으로 나타내 보겠습니다.
states=rownames(USArrests)
hist(nchar(states), main = "Histogram", xlab = "# Chars")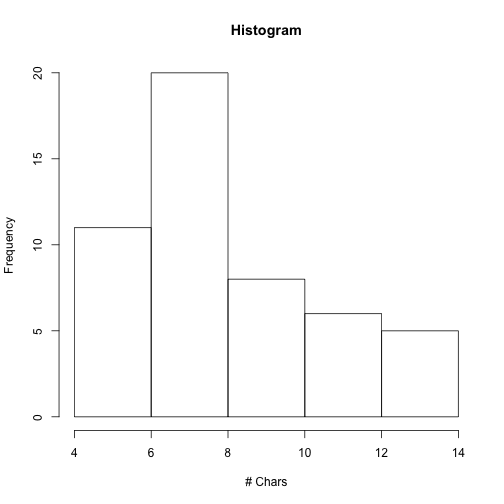 그럼 이번엔 주 이름에서 모음의 분포는 어떻게 될까요?
그럼 이번엔 주 이름에서 모음의 분포는 어떻게 될까요? gregexpr을 이용해서 해당 패턴이 언제 등장하는지 알 수 있게 됩니다.
pos_a = gregexpr(pattern = 'a', text = states, ignore.case = T)
head(pos_a)## [[1]]
## [1] 1 3 5 7
## attr(,"match.length")
## [1] 1 1 1 1
## attr(,"useBytes")
## [1] TRUE
##
## [[2]]
## [1] 1 3 6
## attr(,"match.length")
## [1] 1 1 1
## attr(,"useBytes")
## [1] TRUE
##
## [[3]]
## [1] 1 7
## attr(,"match.length")
## [1] 1 1
## attr(,"useBytes")
## [1] TRUE
##
## [[4]]
## [1] 1 4 7
## attr(,"match.length")
## [1] 1 1 1
## attr(,"useBytes")
## [1] TRUE
##
## [[5]]
## [1] 2 10
## attr(,"match.length")
## [1] 1 1
## attr(,"useBytes")
## [1] TRUE
##
## [[6]]
## [1] 6
## attr(,"match.length")
## [1] 1
## attr(,"useBytes")
## [1] TRUEhead(states)## [1] "Alabama" "Alaska" "Arizona" "Arkansas" "California"
## [6] "Colorado"보시면 아시겠지만, pos_a list에 해당 패턴이 등장하는 index를 가지고 있습니다. 예를들면, ‘Alabama’의 경우, ‘a’는 1, 3, 5, 7번째에 등장하기 때문에, 그 값들을 vector로 가지고 있습니다. 만약 ‘a’를 가지고 있지 않다면, 오직 -1만 값으로 가지고 있습니다. 따라서, 각 list원소의(vector이겠죠?) 첫번째 값이 양수이면 ‘a’가 존재한다는 얘기이므로 해당 vector의 크기는 ‘a’가 등장하는 횟수가 될 것이므로 이를 sapply함수를 이용하여 각 list원소마다 적용해줍니다.
num_a = sapply(pos_a, function(x) ifelse(x[1] > 0, length(x), 0))
num_a #이렇게하면 각 주 이름에 'a'가 몇번 등장하는지를 알아낼 수 있습니다.## [1] 4 3 2 3 2 1 0 2 1 1 2 1 0 2 1 2 0 2 1 2 2 1 1 0 0 2 2 2 1 0 0 0 2 2 0
## [36] 2 0 2 1 2 2 0 1 1 0 1 1 1 0 0반면 stringr의 package에 str_count함수를 이용하여 쉽게 위와 같은 결과를 얻을 수 있습니다.
library(stringr)
str_count(states, 'a')## [1] 3 2 1 2 2 1 0 2 1 1 2 1 0 2 1 2 0 2 1 2 2 1 1 0 0 2 2 2 1 0 0 0 2 2 0
## [36] 2 0 2 1 2 2 0 1 1 0 1 1 1 0 0이게 위에서 구했던 결과와 차이가 나는 이유는, ignore.case의 옵션이 없기 때문입니다. ‘A’를 카운트하지 않겠죠? 따라서 tolower를 통해 모두 소문자로 변환하면 정확히 같은 결과를 얻을 수 있습니다.
str_count(tolower(states), 'a')## [1] 4 3 2 3 2 1 0 2 1 1 2 1 0 2 1 2 0 2 1 2 2 1 1 0 0 2 2 2 1 0 0 0 2 2 0
## [36] 2 0 2 1 2 2 0 1 1 0 1 1 1 0 0str_count(tolower(states), 'a') - num_a## [1] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
## [36] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0자, 이제 그러면 전체 모음에 대해서 개수를 파악해볼까요? 방법은 간단합니다. 각 모음에 대해서 개수를 구한 후 모두 더해주면 되겠죠?
#모음을 벡터로 정의합니다.
vowels = c('a', 'e', 'i', 'o', 'u')
vowels## [1] "a" "e" "i" "o" "u"#각 모음의 개수를 저장할 5개의 벡터 공간을 정의합니다.
num_vowels = rep(0, 5)
#각 모음에 대해서 개수를 구해줍니다.
for (i in seq_along(vowels)){
num_vowels_each_state = str_count(tolower(states), vowels[i])
num_vowels[i] = sum(num_vowels_each_state)
}
#마지막으로 이름까지 붙여주면 완벽하겠죠?
names(num_vowels) = vowels
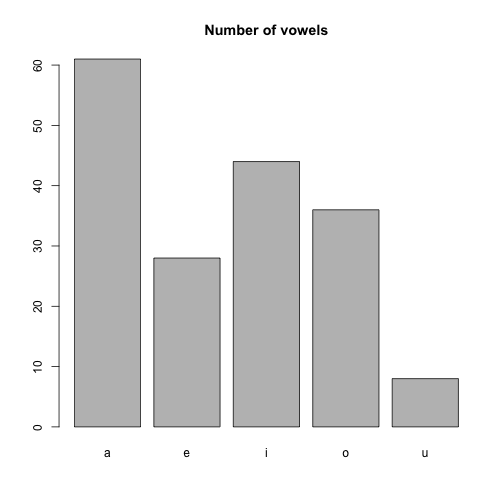
num_vowels## a e i o u
## 61 28 44 36 8마지막으로 barplot으로 개수를 나타내면서 마무리하겠습니다 :)
barplot(num_vowels, main = "Number of vowels")